
How to check whether our machine learning model is working fine or not?
So here come the concept of splitting our data into training, validation and testing set.These categories are used to ensure that the model works well with the general data i.e. it should not only work with training data but also with unknown data.
Training data is the one on which our machine learn its models. In supervised learning models training data will have labels attached to the instances and in case of unsupervised learning models, labels would not be present in the training data.
So after the training phase if we test our model on the same training set it could produce great results but it won’t guarantee generalization. So, here the test data comes for rescue.Testing data is the one on which the model is tested for its general performance and the structure of testing data is similar to the training data.
It is very important to notice that the testing data can’t be used for training else the model cannot be tested for generalization. And it’s very crucial to test our model otherwise we cannot figure out whether our model has learnt the behaviour or just memorized the data i.e. over fitting.
Now we have data to train and test the model, so what is this validation dataset?
Validation dataset is another very important part of data which is used to tune the hyperparameters. Hyperparameters control how the model is learned like model’s complexity , its capacity to learn etc. Hyperparameters are decided by training the model with different hyperparameters values and selecting the one which performs best on the test data and here the test data is the validation set. Validation data is a part of training data itself and the model’s hyperparameters are tuned according to it.
One important thing to notice here is that validation data is a part of training data so it could not be used to test the generalization of the model.
Is it good to tune the hyperparameters on the basis of only a small part of data?
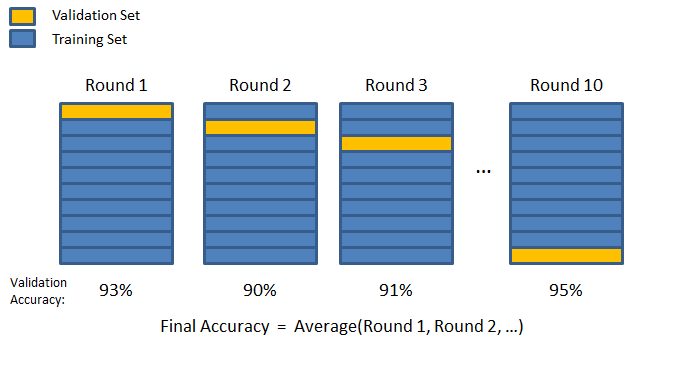
>> No, that’s why we have the concept of K fold cross-validation.In this process of validation we split the training data into k number of “folds” and train the model with k-1 number of folds to leave one set for validation. So that we could train the model k times with k different validation sets to generally tune the hyperparameters.This process is playing a great role in improving the general behaviour of the machine learning model.
How to select the value of k?
If the value of k is very small then our model will be biased and if the value of k is very high then the model will suffer from high variance. So the value of k must be chosen wisely and generally it is suggested to use k = 10.
Python implementation of train/test split :
from sklearn import svm
from sklearn import datasets
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
clf = svm.SVC()
x,y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(df, y, test_size=0.2)
clf.fit(X_train, Y_train)
clf.score(X_test, Y_test)
Python implementation of k-fold cross validation:
from sklearn import svm
from sklearn import datasets
from sklearn import cross_validation
iris = datasets.load_iris()
clf = svm.SVC()
x,y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(df, y, test_size=0.2)
model = clf.fit(X_train, Y_train)
scores = cross_validation.cross_val_score(model, df, y, cv=10)
print (“Cross-validated scores:”, scores)
>> Cross-validated scores: [ 0.4554861 0.46138572 0.40094084 0.55220736 0.43942775 0.56923406]
Follow for more such updates! Happy reading!

Leave a comment