
Regularisation is a technique to solve the problem of overfitting in machine learning. It focuses on reducing the complexity of the model by keeping the weights normal and regular.
Say, your model learns from training so perfectly that it gives 100% accuracy on that training dataset but it lacks generalization i.e it will fail on any other dataset. This happens because of overfitting where the model is trying to learn the data points instead of learning the behaviour.
Example:
Syria is smaller than Germany, True
North Korea is smaller that United Kingdom, True
Philippines is larger than Norway, False
Singapore is smaller than Germany, True
So from the above data set if model is complex and learn every data set it could learn that all Asian countries are smaller than all European countries, but this is not true. This is because of overfitting and regularization focuses on reducing overfitting. Regularisation assures that:
– No feature is assigned a very high weight as a small change in that feature would affect the result very much.
– Zero weight is assigned to every irrelevant feature.
– As a result of this it overcomes the problem of overfitting and assigning zero weight to irrelevant features helps in feature selection.
How regularization works?
We all know about cost function which is also known as loss function. In simple optimization process our target is to minimize the cost/loss function such as least square function (min(y-(W[i]*x)^2). But when we apply regularization we add another term to the cost/loss function i.e (lambda/2)*Sum(|W[i]|^p).
The resultant equation:
Minimize(Sum(y-(W[i]*x)^2)+(lambda/2)*Sum(|W[i]|^p))
Here W is the weight and p is regularization parameter that can be 1 or 2.
There are two different types of loss functions : L1 & L2
L1 loss function is also known as LAD(Least Absolute Deviation). It is basically minimizing the sum of the absolute differences (S) between the target value (Y[i]) and the estimated values (f(x[i])):
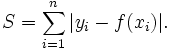
L2 loss function is also known as LSE(Least Squared Error). It is basically minimizing the sum of the square of the differences (S) between the target value (Y[i]) and the estimated values (f(x[i]):
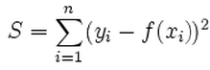 .
.
On the basis of these loss functions regularization is also categorised into 2 types: L1 & L2
The difference between the L1 and L2 is just that L2 is the sum of the square of the weights, while L1 is just the sum of the weights. As follows:
L1 regularization –
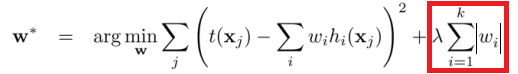
L2 regularization –
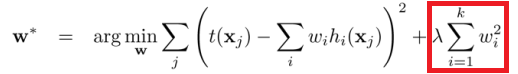
Now that we have a clear picture of what L1 and L2 regularisation are it won’t take much to understand about Lasso and Ridge regression .
Ridge Regression:
Ridge regression performs L2 regularization i.e. it adds penalty equivalent to square of the magnitude of coefficients.
The main aim of ridge regression is to minimize : Least Square Objective(LSO) + α * (sum of square of coefficients).
α provides a trade-off between balancing LSO and magnitude of coefficients.
Lasso Regression:
Lasso is an acronym for “Least Absolute Selection and Shrinkage Operator”. Shrinkage here means to assign positive weights to the relevant features and selection means to assign the irrelevant features with zero weight. Lasso regression performs L1 regularization i.e. it adds penalty equivalent to absolute value of the magnitude of coefficients.
The main aim of Lasso regression is to minimize : Least Square Objective + α * (sum of absolute value of coefficients).
α works here in the same manner it works in ridge regression.
α parameter can take various values:
> if α = 0 the optimisation function works same as simple linear regression.
> If α = ∞ all the coefficients will become zero or tend to zero.
> Otherwise the magnitude of α will decide the weightage given to different parts of optimisation function.
Some differences between Ridge and Lasso regression :
In ridge regression no coefficient can become zero but in lasso regression coefficients can become zero because along with shrinkage it also performs feature selection.
Ridge regression is basically used to reduce overfitting as it uses all the features but lasso regression is used where the number of features is very high to get a sparse solution.
Ridge regression works well when the features are correlated but lasso regression selects only one feature out of a group of correlated features.
There is another technique know as Elastic-net which combines both L1 and L2 regularization to balance the advantages and disadvantages of L1 and L2.
Follow for more such updates! Happy reading!

Leave a comment