
What is pipeline? How to use it?
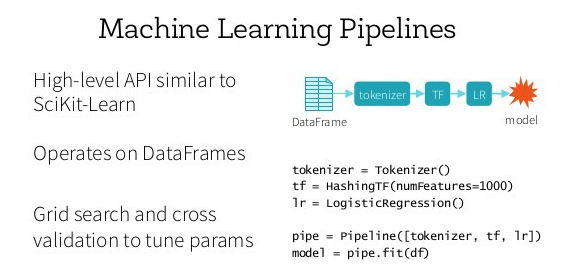
Most of the time there are standard workflows in applied machine learning like data transformation, estimation etc. Pipeline helps us to automate these workflows. This is useful as there is often a fixed sequence of steps in processing the data, for example feature selection, normalization and classification. Pipelines work by allowing for a linear sequence of data transforms to be chained together culminating in a modelling process that can be evaluated. Pipeline gives us a single interface for all steps of transformation and resulting estimator. It encapsulates transformers and predictors inside and it ensures convenience and data safety.
Scikit-learn’s pipeline class is a useful tool for encapsulating multiple different transformers alongside an estimator into one object, so that we only have to call our important methods only once (fit(), predict(), etc). It can be also used efficiently with grid search.
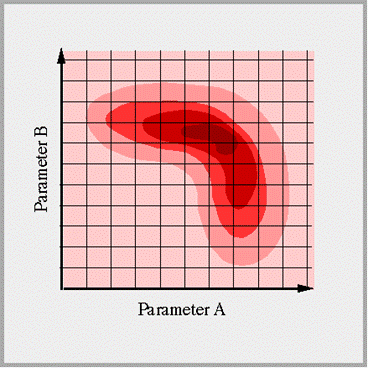
What is Grid Search?
Grid search in basic sense, is a brute force method to estimate hyperparameters. Hyperparameters are parameters of the model that are not learned. For example, hyperparameters in a logistic regression model can be the value of regularization term etc. In sklearn we set hyperparameters through model’s constructor. But it is very difficult to decide what values should be assigned to these hyperparameters, it is done with brute force method. That is why most of the time we use default values but these could not provide optimal results. So here comes Grid Search for rescue, it is the most common method to select hyperparameters values that produce the best model. It takes a set of possible values for each hyperparameters that should be tuned, and evaluates a model trained on each element of cartesian product of sets. It is somewhat computationally costly. But with help of parallel computing this problem can be easily solved.
Python example of Pipeline and Grid Search :
* SMS spam filtering problem using logistic regression
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.grid_search import GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.cross_validation import train_test_split
#Creating pipeline
pipeline = Pipeline([
(‘vect’, TfidfVectorizer(stop_words=’english’)),
(‘clf’, LogisticRegression())
])
#Possible hyperparameters
parameters = {
‘vect__max_df’: (0.25, 0.5, 0.75),
‘vect__stop_words’: (‘english’, None),
‘vect__max_features’: (2500, 5000, 10000, None),
‘vect__ngram_range’: ((1, 1), (1, 2)),
‘vect__use_idf’: (True, False),
‘vect__norm’: (‘l1’, ‘l2’),
‘clf__penalty’: (‘l1’, ‘l2’),
‘clf__C’: (0.01, 0.1, 1, 10),
}
if __name__ == “__main__”:
grid_search = GridSearchCV(pipeline, parameters, n_jobs=-1,
verbose=0, scoring=’accuracy’, cv=3)
df = pd.read_csv(‘data/sms.csv’)
X, y, = df[‘message’], df[‘label’]
X_train, X_test, y_train, y_test = train_test_split(X, y)
grid_search.fit(X_train, y_train)
print ‘Best score: %0.3f’ % grid_search.best_score_
print ‘Best parameters set:’
best_parameters = grid_search.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print ‘\t%s: %r’ % (param_name, best_parameters[param_name])
predictions = grid_search.predict(X_test)
Best score: 0.983
Best parameters set:
clf__C: 10
clf__penalty: ‘l2’
vect__max_df: 0.5
vect__max_features: Nonevect__ngram_range: (1, 2)
vect__norm: ‘l2’
vect__stop_words: None
vect__use_idf: True
The above output provides the best hyperparameters that were used to tune the model.
Follow for more updates! Happy reading!

Leave a comment